-

-
Oh wow, that SD card slot … I mean, how did that get past design for pairing with an apple system? (It should be vertically centered with the USB cards…)? I like Satechi’s designs in the past and they’ve seemed better than this.

-
I love the organization of this tab structure. By increasing year (wrong) and by string name of semester (wrong!). It’s just a little thing that illustrates the care developers of these CMS systems for courses show for their users.

-
Why isn’t there an at home test for norovirus?
-
Want to make errors like this arstechnica.com/tech-poli… go away? Pass a law that makes companies required to pay the difference if they make a billing error.
-
Why does my wemo rule “sunset to 21:30” think sunset is at noon in Indiana? We aren’t that far north!!
-
Just got a automated speed enforcement warning issued by Chicago for the wrong license plate number! (Real value: O, they read D and matched to us). Wasn’t in Chicago on that day! Will we prevail in contesting it?
-
Just had to reboot the TV remote again. Remember when you just needed to change batteries?
-
Wouldn’t this be “lake salt” then?

-
I can’t get away from ODEs even when I listen to music.

-
So it seems like #julialang sysimages have an implicit size limit of 2GB on amd64 systems. :( This arises because the maximum offset in the position independent code instructions is a signed 32bit integer. Bummer. gross details at: github.com/JuliaLang…
-
Trying to compile a #julialang sysimage with ~170 packages is … interesting! Still haven’t succeeded. Lots of writing bisection code to figure out which package is causing a failure.
-
Our son was whistling the mission impossible song. Me: how do you know that song? Him: mark rober (ie @crunchlabs.bsky.social )
-
In case anyone else would like the math about turkey prices that the New York Times thinks is too hard to understand.
I did a quick spot check but it could still be wrong.
https://chatgpt.com/share/67472b0e-4fbc-8006-b17c-5b003709ba80
-
Co2 meters are fun to play with when you get dry ice :)

-
Homemade tonkotsu ramen tonight.

-
Does anyone know if Apple’s new passwords app (iOS 18/macOS 15) has some way to access the passwords in linux? (e.g. windows client via wine??)
-
Helpful links from a recent trip to Japan!
www.thetokyochapter.com/kid-frien… Sadly, we didn’t get to eat at any of these :(
JapanTravelTips on reddit
-
Why do searches for the phrase “global south” peak in April? trends.google.com/trends/ex…
-
Even ChatGPT failed to help me debug the damn tab problem in a makefile.
-
Why is swift so hard? I just want to read a 30GB gzipped file line by line… this is just a few extra characters in python/julia…
-
In Science: Quantifying methane emissions from US Landfills by Cusworth et al.
It’s always surprising when you learn that obvious things aren’t being done, or at least aren’t standard. In this case, it’s using the best tools to measure how much methane is coming from landfills. In news that will shock no one, actually measuring this shows that it’s higher than “bottom up modeling” would suggest.
This is a fairly readable paper in Science. Kudos to the authors.
The team behind this paper is the carbon mapper team. The required methane emissions test is someone walking around with a flame ionization detector to find hotspots. The team behind this paper hired aircraft with higher resolution sensors that are designed to spot methane in the air through its impacts.
A key component of their findings relates to higher temporal frequency showing persistent emissions over time.
Anyway, look around the carbon mapper data to see where the methane is coming from nearby you! In our case, it’s from a few landfills. The team behind this is planning to launch a few satellites to improve the temporal resolution of the data (at the cost of reduced detection thresholds)
-
This is a bizarre result from Google.
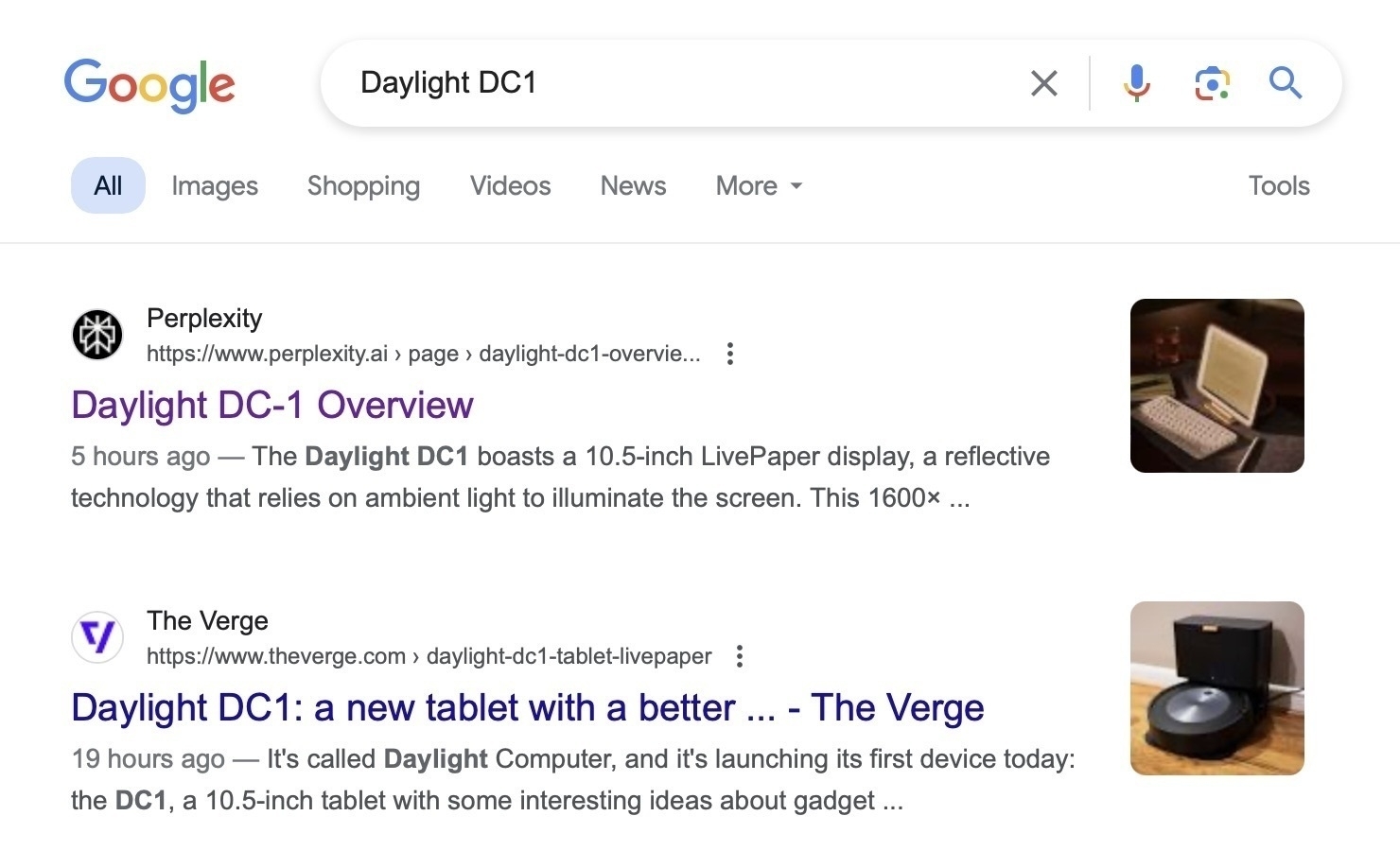
Why is another search engine first? Why is the picture wrong on the second?
I wanted the kickstarted page.
-
Does anyone else have serious reservations about anonymously sharing code for paper review these days?
{kind=link}
subscribe via RSS